What I learned about selling to technical buyers from 289 revenue leaders



Over the last few years, I’ve spoken with hundreds of CMOs, CROs, and other GTM leaders at software infrastructure companies. All of them worked at B2B companies who are selling to technical teams such as R&D, security, DevOps, or data engineering, and I was meeting them as part of my research and validation process for Onfire (and some even became our first customers).
Across these conversations, I noticed three big trends in the market - and these played a major role in what we eventually built. Let’s take a look.
1. No one trusts 3rd party data
Let’s say you’re selling a telemetry pipeline tool. Where do you find buyers? A large company might have hundreds of people with variations of “software engineer” in their job title, but only a handful of them would ever be interested in evaluating telemetry pipelines; of those, you might only be looking for companies who are working in specific cloud platforms, who have a certain scale of data, and who would be willing to consider a commercial solution (rather than OSS). And then, you also want to reach the 5% who are in the market right now.
At this point, you’re probably going to reach for two categories of tools: data providers like ZoomInfo or Apollo, or intent platforms like 6sense or DemandBase. These tools promise to give you a list of companies using the technologies that you work with, prioritized by buying intent, along with the phones and emails of potential decisionmakers. If this data is accurate, that’s a massive win - your BDRs will know exactly who to target, and your marketing team can run precision ABM campaigns that minimize waste. But the data is nowhere near accurate, and everyone knows it.
“Technographics” are a guesstimate based on random keywords found in job descriptions, or frontend scripts scraped from websites. Intent signals are vague web interactions combined with questionable IP data. Buyer personas are inferred from LinkedIn titles.
Everyone is scraping the same job boards and company pages, or repackaging the same data sourced from a handful of providers.
Nobody actually thinks this data is granular or accurate enough for targeting technical niches, but everyone is using it anyway because “it’s better than nothing.” The result is tremendous waste.
How this changed what we built
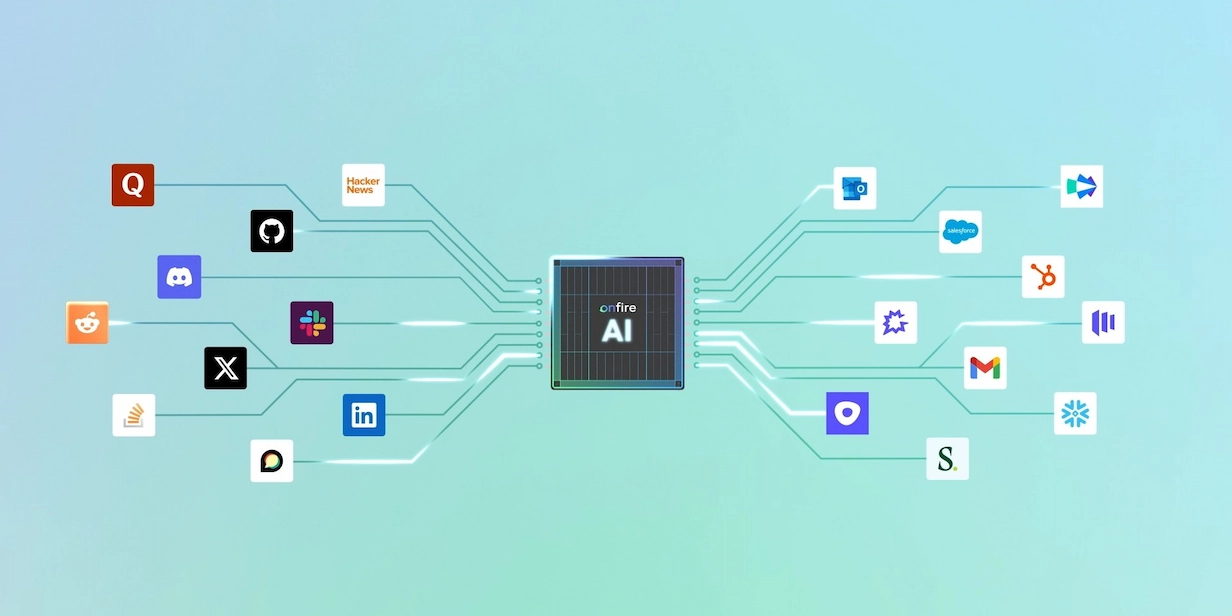
The gap between what technical B2B sellers need and what data providers were offering was the the core insight that led us to create Onfire. Instead of relying on the same data as everyone else, we built industry-first capabilities to collect data from sources such as Reddit, OSS adoption, GitHub forks, and other engineering-centric channels. We allow customers to combine this with their own data (such as product usage), and create a uniquely accurate view of the technical buyers they sell to – essentially rebuilding the data layer from the ground up, with a vertical rather than horizontal approach.

2. Everyone is using LLMs… in the wrong ways
While some sectors are lukewarm about LLMs, my impression is that revenue teams are actually enthusiastic adopters of tools like ChatGPT – whether that’s for simple time saving such as proofreading sales messages, or far more complex use cases like account prioritization and outreach strategies. But while adoption is high, it’s not always effective: people overestimate what they can achieve just by prompting a chatbot, and underutilize the real power of agentic AI tools.
I’ve seen SDRs ask ChatGPT to “create a list of 100 companies who are using embedded C++, and the relevant buyers in these companies”. Chat was happy to produce a list – but unfortunately, 60-70% of it was hallucinated. No amount of prompt engineering will fix this because the “correct” answer does not exist in the training data or the open web. This list can only be inferred from clues and scraps of data that aren’t always publicly available; you need to combine sources, eliminate noise, resolve identities and conflicts; it’s a data science project in its own right. LLMs were not designed to complete this task when responding to a prompt – and even the most sophisticated models simply do not have access to this data.
More advanced implementations are not always more successful. RevOps teams are building AI-powered automations with tools like n8n and Clay, where LLMs are used for tasks such as summarizing account data or drafting personalized emails. AI SDRs promise to fully automate prospecting with hands-free personalization; the results have been mixed at best. It all comes back to the data question: if all of the LLM work is done based on partial, inaccurate, or outdated information, the entire thing breaks down, even if the workflow is immaculate and the most powerful AI model is used. And as we’ve seen, most companies simply do not have data they can trust.
How this changed what we built
We understood that revenue teams want to use LLMs and conversational interfaces. But for these tools to be effective, they need context. This is why we’ve introduced the Onfire Agent –an LLM-powered tool that works with the context of the accurate and granular data that we collect, as well as data from the customer’s own systems (CRM, product usage, web analytics). Sales and marketing professionals keep the ChatGPT-like experience, but the answers they get from will actually be useful, without needing to copy and paste huge blocks of text into each prompt.
3. Emergent winners are taking a unified approach to GTM data
It’s not all doom and gloom. While many companies are struggling with go-to-market, others have found winning, scalable approaches to driving new business. There’s no single formula that will guarantee success, but there is a common thread - using a combination of channels, tactics, and data rather than going all-in on any single source.
It’s not pure PLG, pure inside sales, or pure outbound; it’s not a single channel or lead source. Rather, companies are combining tools, data, and approaches to create a unified view of their customers and meet them where they are – while accounting for the unique characteristics of technical buyers. For example, this is how a ~$50M ARR software company combines gifting, partners, open web monitoring, and internal usage data to identify the most qualified accounts, and find the best inroads to a sales call:
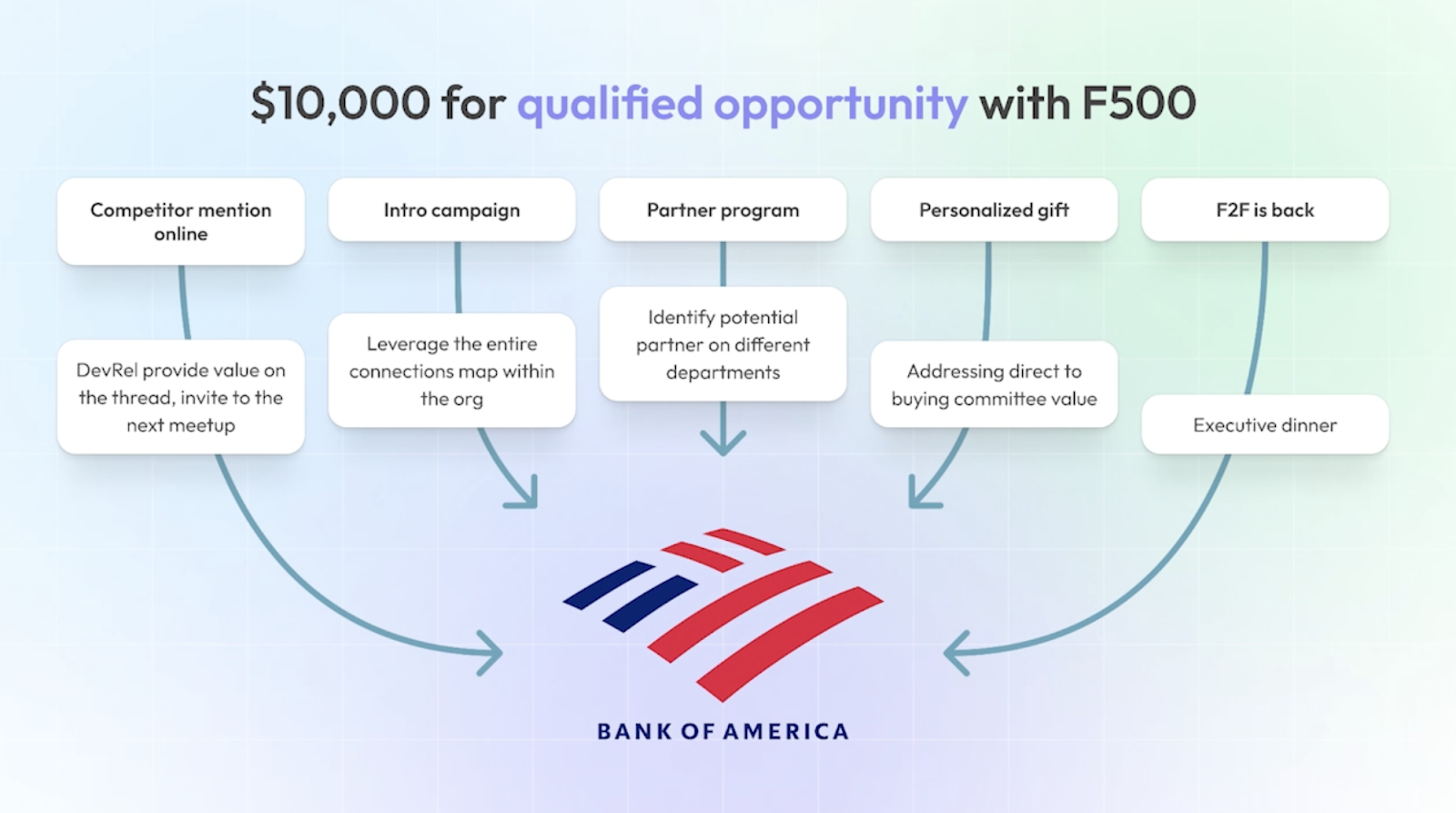
Of course, other companies will have different ways of doing things. But the main idea is that your go-to-market isn’t strictly reliant on third party data, your own CRM and marketing automation tools, or your devrel channels. Each of these can contain important signals, but combining all of them is how you find relevant accounts who are ready to adopt your technology, and reach the person who will be receptive to your message (by the way, this is rarely the hands-on developer who signed up to your free edition).
How this changed what we built
We built Onfire to support and enable these types of hybrid motions, combining data that only we have (such as OSS adoption signals) with unique data that each customer brings to the table (such as usage of their free trial or conversations with their BDRs). We’ve made it easy to bring all of these signals together with bi-directional sync, so that companies have an accurate and highly relevant picture of their audience – and all the tools to reach the right people at scale.
Learn more about Onfire
- Read our launch blog.
- See how Onfire helps sales and marketing leaders.
- Access the Onfire platform by booking a demo.
.webp)

















%20(1).webp)






























.webp)