6 Best Data Enrichment API Providers for Sales, RevOps, and Agents in 2026



Key Takeaways
- A data enrichment API is the programmatic interface to a B2B data provider. The difference from a SaaS UI is the consumer: no human is doing the enriching. Instead, agents, scoring pipelines, and CRM workflows hit it directly.
- The 2022 criteria still matter (match rate, freshness, output fields). What's new in 2026 includes how well an API serves AI agents, machine-readable docs, and whether the provider ships an MCP server.
- Coverage for technical buyers is still a sticking point for many providers. Engineers don't sit cleanly inside the LinkedIn-and-job-title world that powers most enrichment data.
- Check to make sure you get a high match rate during your PoV before committing to a contract.
Your CRM is full of half-records: companies without industries, contacts without titles, and leads without phone numbers. That leaves your SDRs with a huge burden of manual research.
Data enrichment APIs promise to automate a lot of that account research so your reps (and AI agents) can be more effective. Here’s what to look for in these products, five ways to get the most out of them, and our take on six providers worth shortlisting.
What Is a Data Enrichment API and When Do You Need One?
A data enrichment API is a programmatic endpoint that takes a thin record, like an email, a domain, or a name, and returns a rich one replete with information like firmographics, technographics, intent signals, and contact details.
With a SaaS tool, a human sits in front of a dashboard and runs lookups. With an API, the consumer is your stack, which might include a CRM workflow, a Lambda function, a lead-routing rule, or increasingly, an AI agent doing research before drafting an outbound message.
Crucially, an agent doesn't read marketing copy or watch a demo. Instead, it sees the OpenAPI spec, the response schema, and the rate limit, and either succeeds or fails. If your provider's API is half-documented or returns inconsistent JSON, your agent's reliability drops with it.
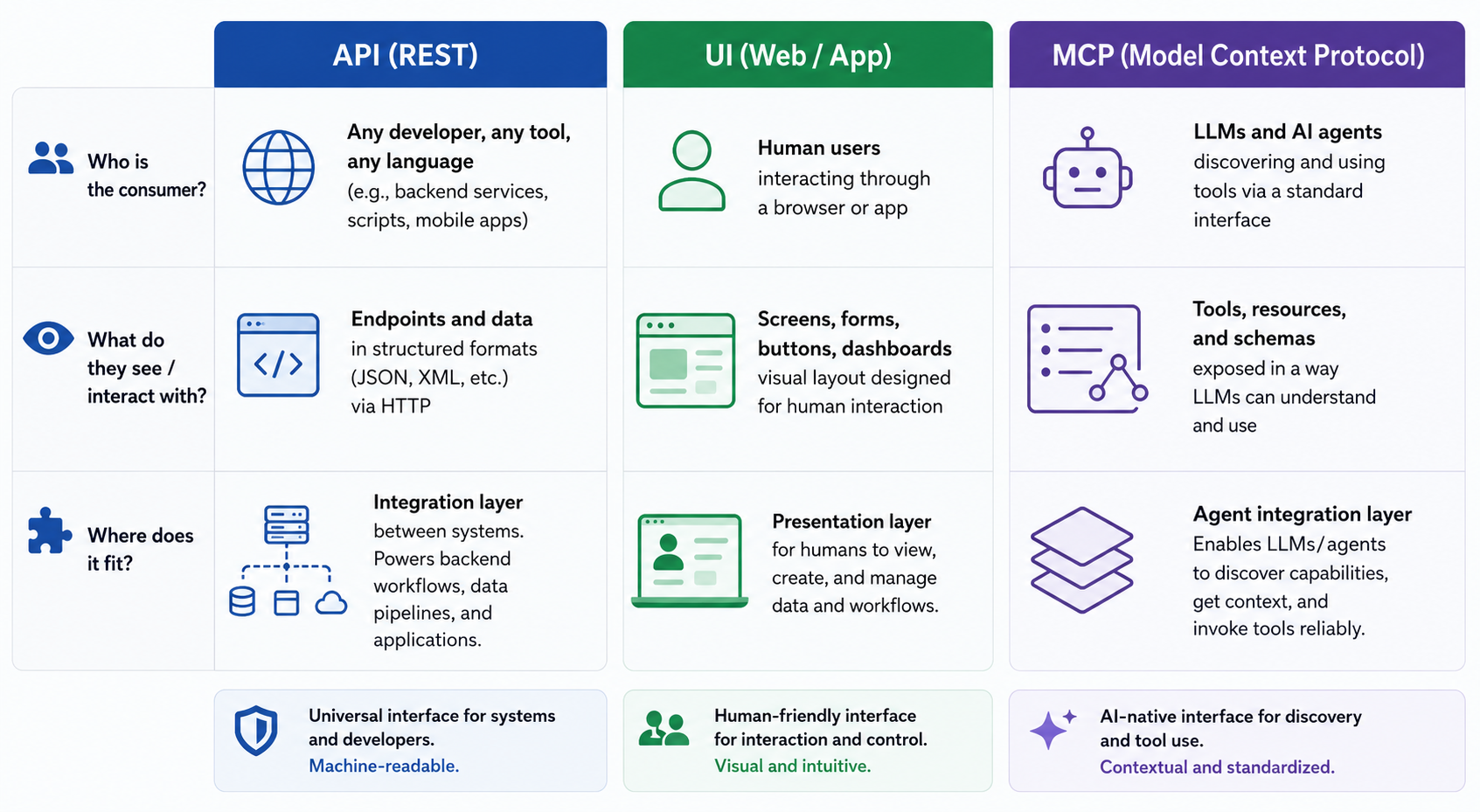
API vs. MCP
It may be worth distinguishing APIs from MCPs, as these distinct terms often get conflated. A REST API is a universal interface that can be called by any language and any tool. An MCP server (Model Context Protocol) is a layer designed specifically for LLMs and AI agents to discover and use tools through a standard interface.
Because you’ll likely have both humans and AI agents working with data for years to come, a good evaluation should look at both REST for traditional pipelines and MCP for agent-native use.
What to Look for in a B2B Data Enrichment API in the Agentic Age
If you’re evaluating solutions, these are your need-to-haves:
1. Data freshness
Refresh cycles range from quarterly to event-based. If you’re routing inbound leads from a webform, monthly refreshes are fine. However, if you’re tracking job changes or funding to time outreach, you need closer to real time.
2. Coverage for technical buyers
Many legacy providers treat LinkedIn as the source of truth, but most engineers (especially outside North America) don’t curate their profiles. To figure out which engineers contribute to OSS, attend Re:Invent breakouts, or discuss vendor offerings on Hacker News, you need data from those places.
3. Match rate
The match rate is the percentage of inputs that come back useful, and it’s something you should test during a PoV. If you get below 60% on your ICP, you’ll need another solution.
4. Output fields
Firmographics, technographics, and intent are non-negotiable, but the question is whether you get usable values, not just keys with nulls.
5. Rate limits and pricing
Per-credit pricing is the norm. However, watch for bulk endpoints rate-limited at one-tenth the per-minute cap of single-record calls, "fair use" throttling on plans labeled unlimited, and credits that expire monthly with no rollover.
6. Integration friction
REST with JSON and an OpenAPI spec are need-to-haves, but nice-to-haves go beyond to include SDKs in the languages your team writes, sandbox accounts that don't burn production credits, clear error responses, and docs an LLM can read without hallucinating. And of course, an MCP server is a meaningful plus.
The Best Data Enrichment API Providers in 2026
We work with many of these providers hands-on, and others we’ve discussed extensively with customers on calls. Here’s our take on the best providers in 2026.
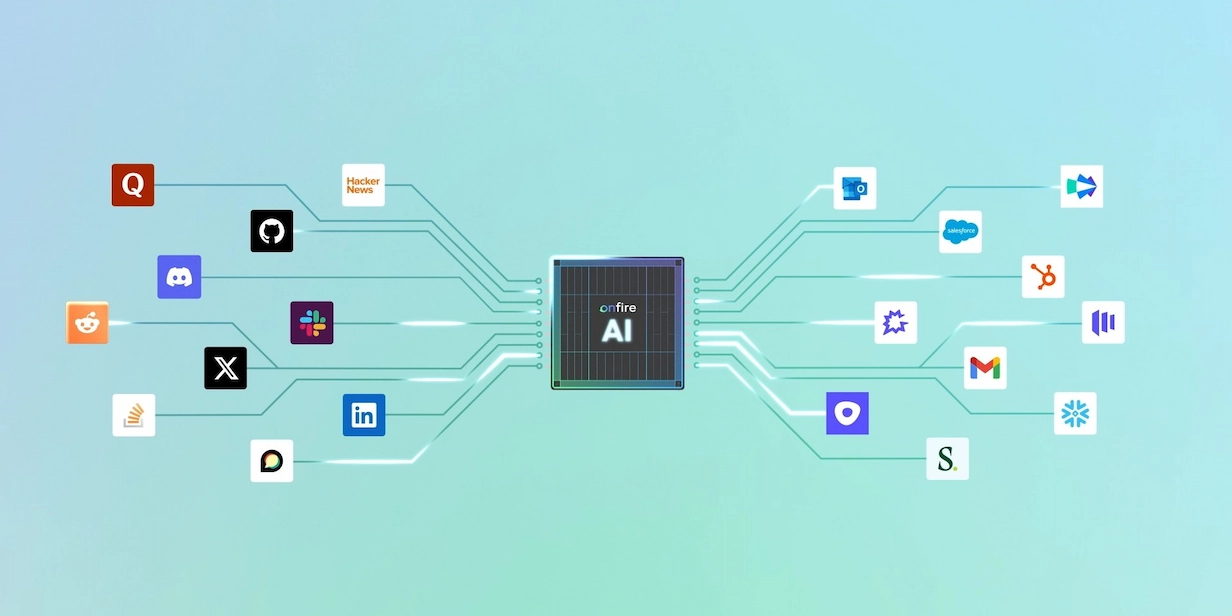
1. Onfire
Onfire’s API serves data on 50 million engineers, 5 million daily events, and over 100,000 places technical buyers actually spend time: GitHub, Stack Overflow, Discord, Slack, Reddit, X, and event platforms like Luma and Meetup. The API returns prospect-level technographic and intent data so you know which engineers at an account contribute to which OSS projects, who attended a relevant KubeCon talk, and who recently posted a question that signals a buying problem.
2. People Data Labs
PDL offers clean REST design, predictable JSON, SDKs in Python, Node, Go, Ruby, and Java, an interactive explorer, and as of late 2025, an MCP server live across all plans. The dataset is close to 3 billion person records and 100 million companies. However, PDL is infrastructure, not a workflow, so SDRs can’t use it without an engineering layer.
3. Apollo.io
Apollo's REST API covers people and organization enrichment, search, and sequencing. The People Search endpoint famously doesn't consume credits, which lets you filter to a tight ICP before spending on enrichment. However, API access requires the Organization plan, which is (at time of publication) $119/seat/month at minimum.
4. ZoomInfo
ZoomInfo has 250 million contacts and 100 million companies in its database, though most of these are in North America. The API supports enrichment, search, and intent, and the Salesforce and HubSpot connectors are mature. However, data refresh is asynchronous and out of your control, and some features, like intent signals, are priced separately.
5. Clearbit (now HubSpot Breeze Intelligence)
Clearbit had fairly popular standalone APIs, but they’re no longer available to new customers. Now, you need a HubSpot subscription to use Clearbit’s enrichment, making it impractical for non-HubSpot customers.
6. Clay
Clay isn't strictly a data provider. Instead, it's a workflow engine that orchestrates 150+ providers (including all five above) into waterfall enrichment cascades. It uses an HTTP API for table operations and has AI columns that combine enrichment results with web research and LLM logic.
5 Ways to Get the Most Out of Your Lead Enrichment API Integration
Lead enrichment can get pricey, so it’s best to be thoughtful about your approach. Here are five proven strategies:
1. Enrich at the moment of truth, not in nightly batches. Fresh data is worth credits when a lead hits your webform, when an account triggers an intent signal, and when a contact changes jobs. Nightly batch enrichment of a CRM that's already 90% accurate, on the other hand, is mostly waste.
2. Factor in data decay. A typical B2B database loses 2–3% accuracy per month from job changes alone. Unless your solution has fresh data, you’ll need to plan data refreshes or you’ll be stuck with old signals.
3. Alert on signal changes. Enrichment APIs can alert you to changes that signal buying intent. A new VP of Engineering, a funding round, or a new repo on GitHub matching your category are all important signals. Build webhooks that fire when a watched field changes, and route the alert to whoever owns the account.
4. Give agents the MCP server, not a hand-wrapped REST call. When the provider ships one, agents discover tools and field schemas through a standard interface rather than depending on tool definitions you wrote into a prompt six weeks ago.
5. Cap enrichment calls per agent run, and make the limit visible to the agent. A confused agent that's allowed to call enrichment recursively will burn a week of credits in an afternoon. Most agent frameworks let you set a hard budget per task, and three to five enrichment calls per lead is usually enough for a research-then-draft loop. Beyond that, the agent is fishing, and the additional credits aren't producing better outreach.
Acting on Rich Data with Onfire
Automated data enrichment is not magic, but when it works, it saves you from spending most of your day on manual research. The key is to use data providers that track where your buyers spend their time and serve insights to you in the workflow you already use.
To see how your SDRs can spend more time selling with enriched data, see what Onfire can do for you.
FAQ
What's the difference between a contact enrichment API and a company enrichment API?
Contact enrichment takes a person identifier (email, name, LinkedIn URL) and returns a fuller profile: title, role, contact details, sometimes career history. Company enrichment takes a domain or company name and returns firmographics, technographics, and company-level signals. Most providers offer both as separate endpoints, and most teams need both in the same workflow.
How do you handle rate limits when enriching large lists via API?
Use bulk endpoints where supported, but expect their per-minute cap to be one-tenth of single-record. Build pacing into your job runner with exponential backoff on 429 responses. Most production teams stage enrichment: a cheap lookup first, then a second pass for expensive fields like mobile numbers only on records that cleared the first filter.
Which data enrichment API has the best coverage for engineering and DevOps personas?
Onfire is purpose-built for this and tracks signals the LinkedIn-derived providers structurally miss, including OSS contributions, Discord and Slack activity, Stack Overflow patterns, and technical event attendance.
Is it better to enrich leads in real time at capture or in batch after the fact?
Real time at capture is almost always better. The routing, scoring, and personalization decisions made on the enriched record are the actual value of enrichment, and they only happen if the record is enriched before those decisions get made. Batch is fine as a backfill for legacy records but the wrong default for net-new leads.
How do you measure whether a data enrichment API is actually improving pipeline quality?
Measure two things: match rate on your specific ICP (run 500 representative records through the API and check the response), and downstream conversion (do enriched leads convert at higher rates than non-enriched controls?). The first tells you the provider can serve your data; the second tells you the enrichment is actually changing decisions. Without both, you're paying for fuller fields, not better pipeline.
.webp)













%20(1).webp)






























.webp)